Optimizing Web Scraping: When to Use (or Not Use) Headless Browsers

When browsing the enormous amounts of articles available about web scraping, you'll often find tutorials about headless browsers. You must extract data from X? Oh, just use Selenium, Playwright, or Puppeteer. ("X" being a random website, not the social network.)
If those solutions will work in most cases, they don't consider the amount of resources you need to run them. Running a full-blown browser will take much more CPU and RAM than you would if you sent requests through an HTTP client.
But wait, how can I extract information from a page where the data doesn't appear in the HTML body and, therefore, is unavailable through an HTTP client? You may ask, rightfully.
That's a valid point. The data you want to extract may not be fetchable by sending a GET request to the target page. However, that doesn't mean you should use a headless browser. In fact, a headless browser should be the last resort for web scraping.
First, let's understand the difference between server-side rendering and client-side rendering and how they influence the way we scrape data from the web.
Decoding Web Page Construction: Server-Side vs. Client-Side Rendering
Web pages can be built in different ways. A server can generate some, while a "client" can create others. Some might even have a bit of both. Let's see those differences in detail and why they're essential for you in the context of web scraping.
Server-Side Rendered Pages
A web server takes care of building a server-side rendered page. It will structure the entire HTML of the page before sending it to the client. (You can replace "client" with "browser".)
When the browser receives the response from the server, the page is already complete. The browser doesn't need to execute extra instructions to finish building it. It also doesn't require additional requests to fetch data from other sources.
That scenario is straightforward for web scraping. Since the whole page's structure is done, you can extract the data from it. Thanks to a GET request to the page, you can fetch the HTML, parse the response, and apply the appropriate selectors. And voilà, you just got the data you needed.
You might have heard of Static Site Generation (SSG) or Static Generated Pages. While this is yet another rendering method of web pages, you can treat this scenario the same way you'd do with server-side rendered pages in the context of web scraping.
Client-Side Rendered Pages
The client-side rendered pages work differently. Instead of having a complete HTML page returned to your browser, it'll receive a "partially" built page from the server.
In the most extreme cases, the page content can look like this:
When you send a GET request to the page, you'll get the same response as the browser. You won't be able to extract data from it.
Behind the scenes, the browser downloads and executes the JavaScript file in the page's header. JavaScript then builds the page and, if necessary, fetches the data from other endpoints. (Those endpoints can also be referred to as APIs.)
A solution to scrape the needed data would be to simulate the browser's behavior by executing the JavaScript and letting it build the page.
That's where the headless browsers come into play. A headless browser executes the JavaScript, letting it render the page's whole content, allowing you to extract the data via CSS selectors.
Instead of executing a GET request to the target page, your code would start a browser you can control programmatically. This is why this web scraping way can be problematic regarding resources, as web browsers are eager to compute resources.
Mixing Client-Side and Server-Side
It's also possible for a page to have part of it rendered by the server and the rest by the client.
In that situation, you have three options depending on the data you're targeting and which elements are client/server-side rendered:
- The server renders the data you need to scrape; therefore, you can use an HTTP client for the server-side generated pages. In short, you can treat this scenario like a server-side rendered page.
- The browser has to render the target data for you. So you'll be in a situation where you must find a way to execute JavaScript (same as for the client-side generated pages.)
- The target data are split between client and server-generated content. Unfortunately, you'd end up in the client-side rendered pages scenario.
How do you determine whether a page is generated on the client or server?
The easiest way to determine whether a page requires JavaScript execution in your browser is to turn off the JavaScript before navigating to the page you are interested in.
If the data you're looking for is visible, the server generates it. If not, it means it relies on JavaScript to render it.
Disable JavaScript in Chrome
- Open Chrome DevTools
- Press Control+Shift+P (or Command+Shift+P on Mac)
- Type
javascriptin the search input, select Disable Javascript and press Enter.
Disable JavaScript in Firefox
- Go to
about:configin your URL bar - Search for
javascript.enabled - Set it to
false
Scrape client-side rendered data without a headless browser
What if there was a way to access those precious data without rendering the JavaScript? It turns out there might be.
When executed, JavaScript must fetch the data it needs from somewhere. So, if we figure out where JavaScript fetches the data it needs, we can skip the intermediary and get the data without relying on JavaScript.
One of the most common ones would be to request an API. So, the alternative for you would be to do JavaScript's job in its place. You can do it yourself instead of relying on the browser to fetch the data from an endpoint.
An API is one of the most common data sources JavaScript can drain. You can guess which API endpoints are relevant to your needs, reverse-engineer them, and execute the requests yourself.
The easiest way to do it is to observe the network tab of your browser. Open it, and refresh the page you're targeting.
Don't forget to turn JavaScript back on in your browser! Otherwise, the network tab won't show any requests.
If you don't have any filters applied, you should see that your browser fetches many external resources required by the page to work. HTML, CSS, JavaScript, Fonts, etc. are all needed to build the page.
If you filter your requests on XHR, you'll see all the API calls your browser makes on behalf of JavaScript. On large web applications, you might encounter dozens of requests. One way to find the relevant ones for your needs would be to focus on the endpoint path.
Click on the most relevant request, and check out the response it received.
The data format might not fully resemble what you see on the page. On the page, the content is formatted by JavaScript and rendered in a friendly way through HTML. The API response will, in most cases today, return JSON data. So, you might have to do some reverse engineering and try to match the API data with what you're looking for.
If the data you're searching for is not in the response to the request you've investigated, move on to the next one. Repeat the process until you find what you're looking for.
Unfortunately, this is not an exact science. As there are hundreds of ways to build a web application those days, it's impossible to write a step-by-step guide that would work 100% of the time.
However, this technique might be worth it, especially if you scrape extensive data. You'll save time and resources by getting what you want directly from the API.
Let's apply the theory to a real-world situation
Now that we went over the theory, let's take a real-world example and apply what we've just learned.
For our example, let's take the following page.

It's a listing of a popular item on the Steam marketplace.
Imagine we're interested in extracting the data from the following graph.
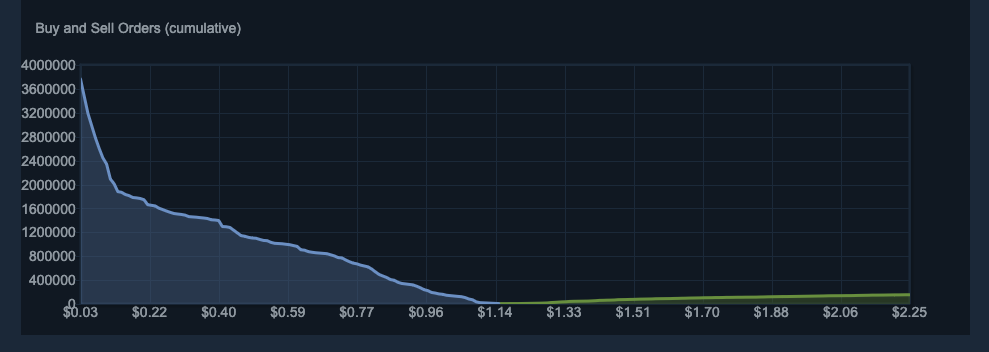
First, we can check how the browser renders the element on the page. Has the server already sent it completely? Or does the browser have to make extra requests to build the graph? Let's disable the JavaScript, reload the page, and see the answer to those questions.
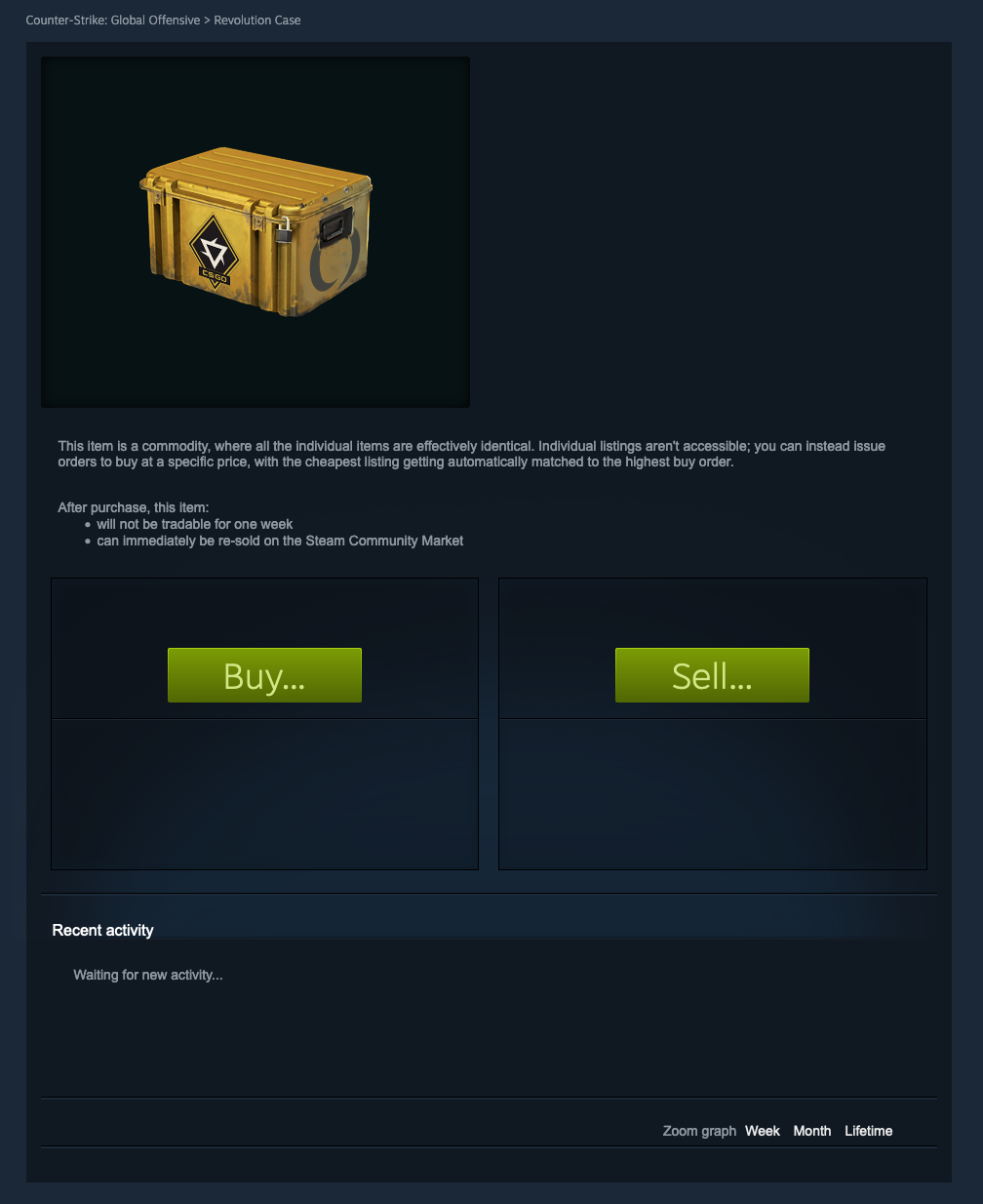
As you can see, the graph we're interested in is gone (as are most of the page's elements). We just confirmed that this element was generated on the client side. Let's try to find where the data is coming from!
Turn JavaScript back on, open your Network tab (filter by XHR), and refresh the page. Initially, you will notice that two requests have been executed.

If you keep the Network tab open, you'll notice that new requests to the same endpoints are sent after a couple of seconds. The page polls the data regularly to update the pages with the latest updates. Since it's hitting the same endpoint, you can ignore the requests beyond the first two.
Click on the first request (to /itemordershistogram), and let's dig into the response.
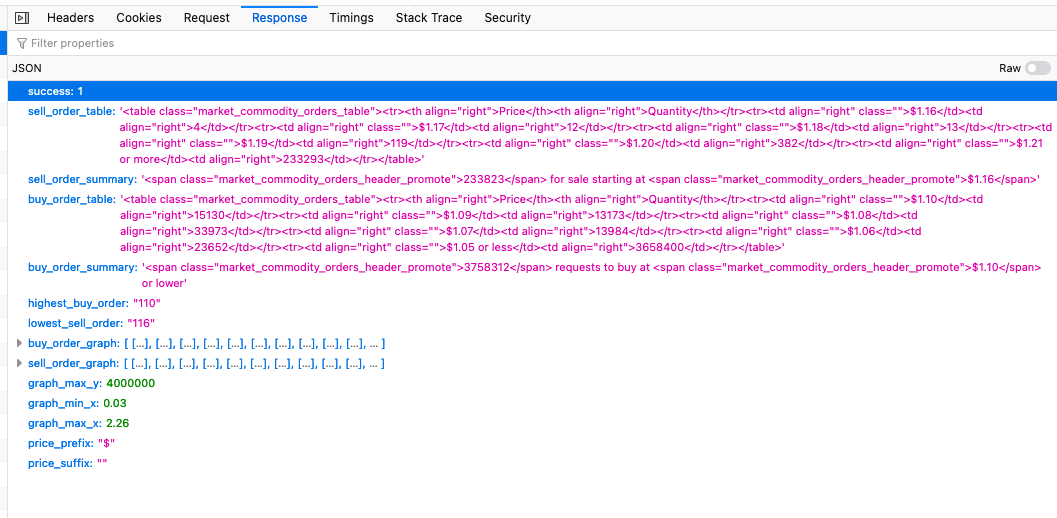
/itemordershistogram endpointIf we analyze the JSON we got back, we see two keys that could correspond to the data we want to extract. buy_order_graph and sell_order_graph look like something that could interest us.
We can confirm that the target data are here if we expand the buy_order_graph.

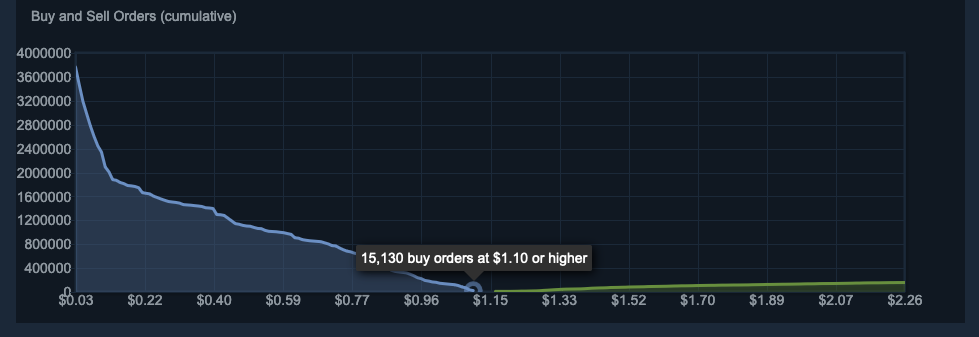
You'll notice that the label appearing when hovering the form is the same as the one in the 0 index of the buy_order_graph. You can inspect further indexes and confirm this is still the case with them. By expanding and investigating, you can discover the same results as well.
We can conclude the data we're targeting are in the response to the request to /itemordershistogram. Therefore, we can reproduce the request we inspected in the Network tab in our code to extract the data.
GET https://steamcommunity.com/market/itemordershistogram?country=CH&language=english¤cy=1&item_nameid=176358765&two_factor=0Of course, that works in the use case I chose, but in other scenarios, it might not be as straightforward as the API can expect some specific headers, or you'll have to set cookies (especially when the API requires authentication). When you encounter a situation where the request you make in your code doesn't work the same way as in the browser, compare the two and see what's different regarding headers, parameters, methods, etc.
Conclusion
We saw the different types of web pages present on the modern web. Before writing a scraping script and using a headless browser "by default," it is worth investigating and understanding how the page is built, as it will help you choose the right tool for the job.
Of course, you can consider using a headless browser in every situation, as it will most likely work in 100% of the cases. But, you'll risk wasting time and resources that could be saved by a small amount of time spent investigating before starting the job.
Thank you for spending the time reading my article. I hope you enjoyed it!

Comments ()